🌐 Webスクレイピングで、情報収集が劇的にラクになる
毎日手作業でコピペしていたデータ収集が、コードを数行書くだけで自動化できたら——そんな未来がPythonのWebスクレイピングで実現できます。価格比較、ニュース収集、リサーチ業務など、あらゆる場面で活躍する強力なスキルを、今日から身につけましょう。
📌 Webスクレイピングとは?
Webスクレイピングとは、プログラムを使ってWebサイトから情報を自動で抽出することです。たとえば、あるテーマパークのサイトに今月のイベント一覧が掲載されていて、「何日に何のイベントがあるか」を自動で取得したい——そんなときにWebスクレイピングを使います。
⚠️ Web APIとの使い分け
データ取得の方法として「Web API」という選択肢もあります。Web APIが公開されているサービスではAPIを優先的に使いましょう。ただし、すべてのサイトでAPIが使えるわけではないため、APIがない場合にWebスクレイピングが活躍します。また、スクレイピングを禁止しているサイトもあるので、利用規約を事前に必ず確認してください。
🛠️ 必要なライブラリのインストール
PythonでWebスクレイピングをするには、以下の2つのライブラリを使います。
- 📦 requests:WebページのHTMLを取得するライブラリ
- 📦 Beautiful Soup(bs4):取得したHTMLを解析・操作するライブラリ
ターミナル(コマンドプロンプト)で以下のコマンドを実行してインストールします。
pip install requests
pip install beautifulsoup4

🔍 HTMLの基礎知識——スクレイピングに必要な最低限の理解
スクレイピングでは、HTMLの構造を理解する必要があります。HTMLはタグと呼ばれる「<div>〜</div>」のような囲みで構成されており、タグにclassやidという属性が付いていることがあります。欲しいデータがどのタグに包まれているかを特定することが、スクレイピングの第一歩です。
Chromeの「右クリック → 検証(デベロッパーツール)」を使うと、任意の要素のHTMLをすぐに確認できます。
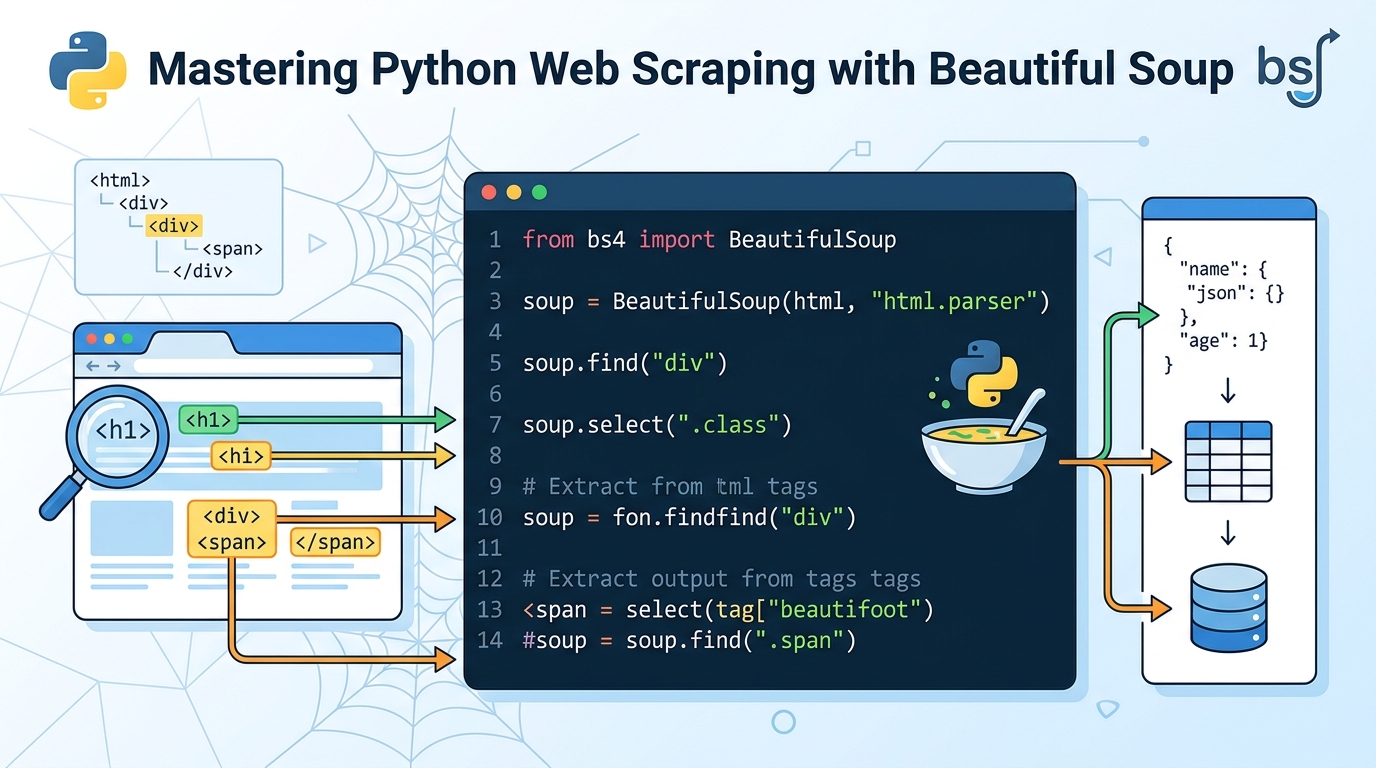
💻 実際のコードで学ぶ Beautiful Soup の使い方
① HTMLを取得する(requestsライブラリ)
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
html = response.textrequests.get(url) でページのHTMLを取得し、response.text でテキストとして受け取ります。
② Beautiful Soupオブジェクトを作成する
soup = BeautifulSoup(html, "html.parser")取得したHTMLをBeautiful Soupに渡してオブジェクトを作成します。第2引数の "html.parser" はPython標準のHTMLパーサーです。
③ 要素を取得する(find・find_all)
- 🔎 find():条件に一致する最初の1つを取得
- 🔎 find_all():条件に一致するすべての要素をリストで取得
# タグ名で取得
tag = soup.find("h1")
# class名で取得
tag = soup.find("div", class_="main-content")
# id名で取得
tag = soup.find("span", id="username")
# すべての li タグを取得
items = soup.find_all("li")④ テキストや属性を取り出す
# テキストを取得
text = tag.get_text()
# href属性(URLなど)を取得
link = tag.get("href")リンク(<a>タグの href 属性)はドメインが省略された相対パスで記載されていることがあります。その場合はベースURLを先頭に付け加えることで完全なURLになります。
⑤ リスト内包表記で複数データを一括取得
links = [a.get("href") for a in soup.find_all("a")]このように書くと、ページ内のすべてのリンクをまとめてリストとして取得できます。さらに取得したURLに再度 requests.get() を適用すれば、リンク先ページのデータも連続して取得することが可能です。


📚 実践ですぐ役立つ!おすすめ学習グッズ
スクレイピングをより深く学ぶためには、書籍や環境構築グッズも大切です。実際に手を動かしながら学べる環境を整えることで、習得スピードが大幅にアップします🚀



























✅ Beautiful Soup 活用チートシート
- 🔹 soup.find("タグ名"):最初にマッチする要素を1件取得
- 🔹 soup.find_all("タグ名"):マッチする全要素をリストで取得
- 🔹 tag.get_text():タグ内のテキストを取得
- 🔹 tag.get("属性名"):タグの属性値(href など)を取得
- 🔹 class_ = "クラス名":classで要素を絞り込む(アンダースコアに注意)
- 🔹 id = "ID名":idで要素を絞り込む
❓ よくある質問 FAQ
🤔 Q1. requests と Beautiful Soup の違いは何ですか?
requests はWebページのHTMLを「取得」するライブラリです。一方 Beautiful Soup は取得したHTMLを「解析・操作」するライブラリです。2つをセットで使うのが基本スタイルです。
🤔 Q2. スクレイピングは法律的に問題ありませんか?
サイトによってはスクレイピングを利用規約で禁止している場合があります。スクレイピングを実施する前に、対象サイトの利用規約や robots.txt を必ず確認しましょう。公開情報であっても、サーバーに過度な負荷をかける行為は問題になる場合があります。
🤔 Q3. find と find_all はどう使い分けますか?
取得したい要素が1件だけなら find()、同じ種類の要素を複数まとめて取得したい場合は find_all() を使います。find_all() はリストを返すので、for文やリスト内包表記と組み合わせて使うのが便利です。
🤔 Q4. 取得したリンクがhttpsから始まっていない場合はどうすればいいですか?
相対パスで記載されている場合があります。その場合は対象サイトのベースURL(例:https://example.com)を先頭に結合することで完全なURLになります。Pythonの文字列結合や urljoin 関数が便利です。
🤔 Q5. JavaScriptで動的に表示されるページはスクレイピングできますか?
requests と Beautiful Soup だけでは、JavaScriptで動的生成されるコンテンツの取得が難しい場合があります。そのような場合は Selenium や Playwright といったブラウザ自動操作ライブラリを組み合わせる方法があります。
🎯 まとめ
PythonのBeautiful Soupを使えば、Webスクレイピングはとてもシンプルに実現できます。requestsでHTMLを取得し、Beautiful SoupでそのHTMLを解析して必要なデータを抽出する——この2ステップが基本です。HTMLのタグ構造を理解し、find() や find_all() を使いこなすことで、日々の情報収集や調査業務を大幅に効率化できます。ぜひ実際にコードを書いて、自動化の快適さを体験してみてください🐍✨

コメント