📄 面倒なPDF作業から解放される未来へ
大量のPDFファイルから特定の文字を探したり、数百ページの資料を1ページずつ分割したり…。そんな、単純だけど時間がかかる「PDFの単純作業」に頭を悩ませたことはありませんか?😭
もし、これらの作業をボタン一つ、あるいはプログラムに任せて数秒で完結できたらどうでしょうか。自由な時間が増え、よりクリエイティブな業務に集中できるはずです。✨
実は、Pythonというプログラミング言語を使えば、PDFの操作は驚くほど簡単に自動化できます。今回は、PDF操作の強力な味方となるライブラリを活用して、業務効率を劇的に向上させるテクニックを紹介します!💻
🛠 PDF自動化を支える2つの強力ライブラリ
PythonでPDFを扱う際、目的によって使い分けるべき2つの主要ライブラリがあります。💡
- PyPDF (pypdf):PDFの「読み込み」「分割」「結合」など、既存のファイルを操作するのに最適です。🔍
- ReportLab:PDFを「ゼロから作成」したり、文字や画像を「書き込んだり」するのに特化したライブラリです。✍️
まずは、これらのライブラリをインストールし、PDF閲覧ソフトであるAdobe Acrobat Readerなどを準備して、自動化の環境を整えましょう!🚀
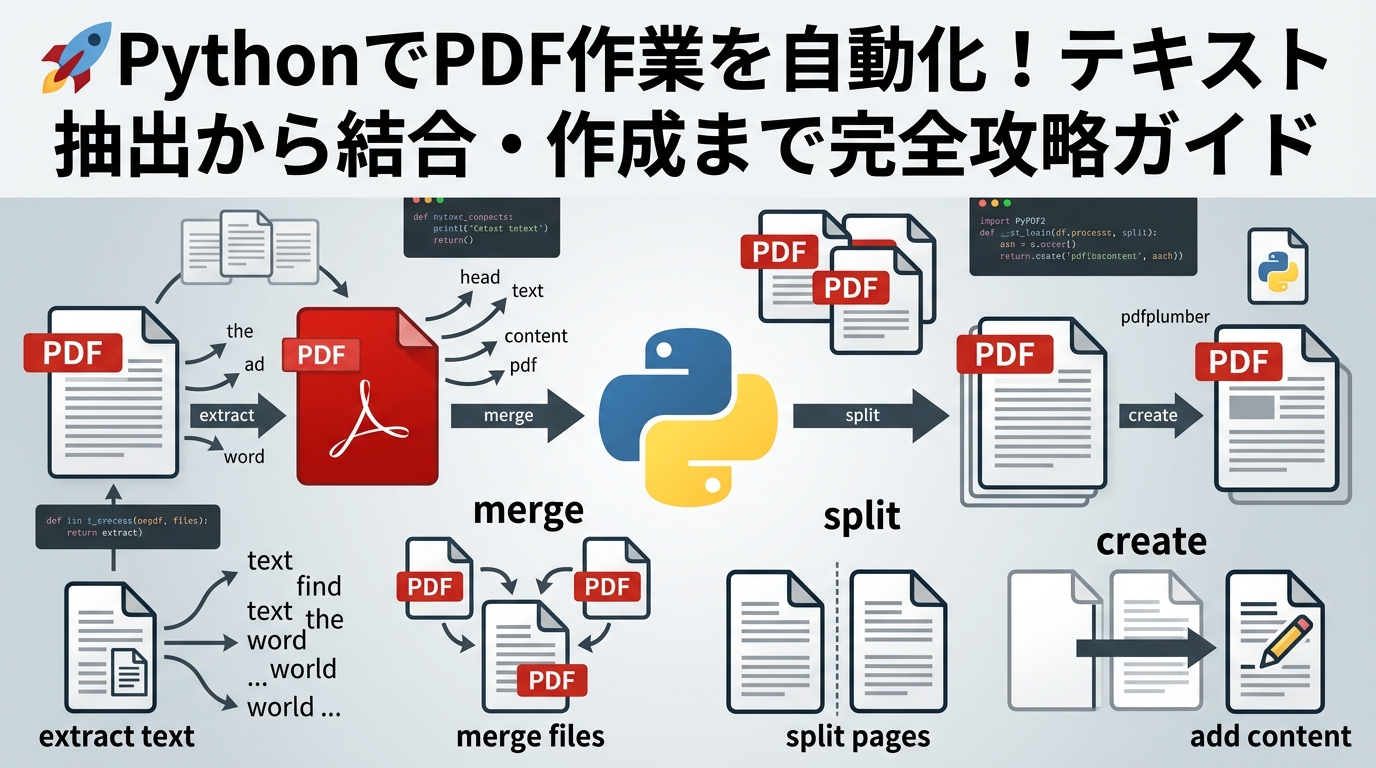
🔍 【実践1】PDFからテキストと画像を抽出する
PDFの中身をデータとして取り出せれば、Excelへの転記や内容の分析が格段に楽になります。📈
テキストデータの抽出とレイアウト保持
PyPDFを使えば、指定したページのテキストを簡単に取得できます。ただし、PDFの構造によっては文字の順番がバラバラになることがあります。😱
ここがポイント!
レイアウトが複雑なPDF(2段組みなど)の場合は、抽出モードを「layout」に設定することで、見た目に近い形でテキストを取得することが可能です。✅
PDF内蔵画像の保存
PDFに埋め込まれたロゴやグラフなどの画像データも、プログラムで一括抽出できます。ページ内のイメージオブジェクトにアクセスし、バイナリデータとして保存するだけで、必要な画像をすべて取り出すことができます。🖼️
✂️ 【実践2】PDFの分割と結合を瞬時に行う
「100ページのPDFを1ページずつのファイルに分けたい」「バラバラのPDFを1つのファイルにまとめたい」といった要望も、Pythonなら一瞬です。⚡
1ページずつの分割出力
PdfWriterクラスを使用し、ループ処理で1ページずつ新しいファイルとして保存します。ファイル名に連番を付けることで、整理された状態で大量のファイルを生成できます。📂
複数ファイルのガッチャンコ結合
appendメソッドを使えば、複数のPDFファイルを指定した順番通りに1つのファイルへまとめることができます。フォルダ内のファイル一覧を取得し、ソートして結合させれば、年度ごとの報告書まとめなども自動化完了です!🤝
✍️ 【実践3】PDFをゼロから作成してデータを書き込む
ReportLabを使えば、請求書やレポートなどの定型PDFを自動生成できます。🎨
文字と画像の配置
Canvasオブジェクトを使い、X座標とY座標を指定して文字(drawString)や画像(drawImage)を配置します。座標感覚を掴めば、自由自在にレイアウトを設計できます。📍
日本語フォントの設定(重要!)
PDF作成時に陥りやすいのが「日本語が文字化けして黒い四角(豆腐)になる」問題です。😱
これを解決するには、日本語対応のフォント(平成覚書W5など)をレジストリに登録し、setFontで指定する必要があります。正しく設定すれば、美しい日本語のPDFが出力されます。🇯🇵
🛒 快適な自動化ライフを実現するおすすめアイテム
プログラミング効率を最大化し、さらに快適なデスク環境を構築するための厳選アイテムを紹介します。🎁
1. 学習効率を上げるPython入門書
基礎からしっかり学びたい方へ。PDF自動化だけでなく、汎用的なスキルが身につく一冊です。📚


























2. コード書きが捗るメカニカルキーボード
打鍵感にこだわったキーボードは、長時間のコーディングでも疲れにくく、モチベーションを爆上げしてくれます。⌨️








3. 作業領域を倍増させるデュアルモニター
左にエディタ、右にPDF閲覧ソフト。画面を切り替える手間をなくせば、開発スピードは格段に上がります。🖥️
















4. 手首の負担を軽減するエルゴノミクスマウス
大量のコードを書き、デバッグを繰り返す日々に。手首への負担を抑える設計で、健康的に開発を続けましょう。🖱️












❓ よくある質問(FAQ)
- Q: プログラミング完全初心者でもPDF自動化はできますか?
A: はい!可能です。😊 PyPDFやReportLabなどのライブラリが優秀なので、基本構文を覚えれば、サンプルコードを組み合わせてすぐに実装できます。 - Q: スキャンしたPDF(画像形式)の文字も読み取れますか?
A: PyPDFだけでは難しいです。😭 その場合は「Tesseract」などのOCR(光学文字認識)ライブラリを併用することで、画像の中の文字をテキスト化できます。 - Q: PDFの結合に最適なライブラリは何ですか?
A: 結合や分割などの操作であれば、シンプルで使いやすいPyPDF (pypdf)が最もおすすめです!🌟
✨ まとめ:PDF自動化で「時間」という資産を手に入れよう
Pythonを使えば、これまで手作業で時間を浪費していたPDF操作をすべて自動化できます。🚀
- PyPDFでテキスト・画像を抽出し、ファイルを分割・結合する 🔍
- ReportLabで日本語フォントを設定し、自由なPDFを作成する ✍️
まずは小さな作業から自動化してみてください。一度仕組みを作ってしまえば、あとはPCがあなたの代わりに働いてくれます。浮いた時間で、コーヒーを飲んだり、新しいスキルを学んだりと、最高のライフスタイルを手に入れましょう!🌈

コメント